

Let Your Data Flow: Streams and Reactive Programming
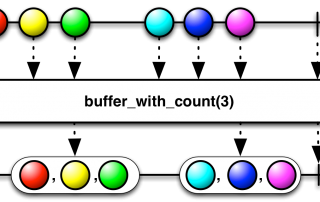
What's all this about ? ReactiveX is a combination of the best ideas from the Observer pattern, the Iterator pattern, and functional programming. Using Rx, you can easily: - Create event or data emitting streams from sources such as a file or a web service - Compose and transform streams with query-like operators - Subscribe to any observable stream and "react" to its emissions to perform side effects Reactive programming has been gaining traction these past few years. Maybe you've [...]