Dimensionality Reduction Tutorials: 1- Principal Components Analysis
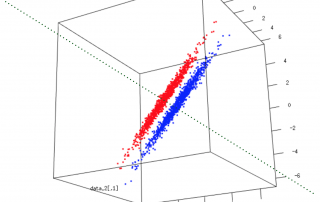
Understanding dimensionality reduction If you use large datasets (transcriptomes, whole genome sequencing, proteomes), sooner or later you will stumble across something called Principal Components Analysis (PCA). PCA is a dimensionality reduction, a family that encompasses many techniques that do just that: reduce the dimensionality. But what does that mean? What are dimensions and why would we want to reduce their number? How about we deal with these questions through an example? The problematic Say we have a hypothetical transcriptome, of a [...]