

Chemical Screen: Evaluating drug sensitivity
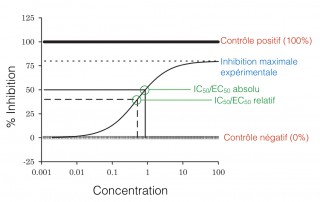
The study of the cellular response to a chemical compound is crucial to the development of new therapeutic drugs. Such an analysis is usually done by a screen experiment where the disease-specific cells (such as leukemia primary cells) are exposed to chemical compound for different concentrations. The response, in the form of sensitivity, of these cells is conventionally quantified by the IC50 or the l’EC50. Here are some notions to keep in mind when we analyze these values. IC50/EC50 : estimate of [...]