Mégadonnées, gros défi
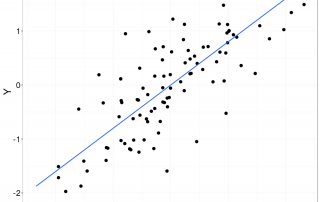
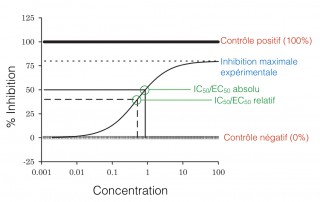
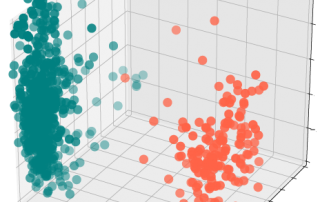
Vous avez certainement déjà entendu le mot mégadonnées. Ou "Big Data". Notamment, si vous avez lu l'article de Simon Mathien sur le site de l'IRIC. (Si vous ne l'avez pas lu, je vous encourage à le lire!) Il existe plusieurs définitions (ou interprétations) du mot mégadonnées qui sont bien résumées par les deux définitions suivantes : Data of a very large size, typically to the extent that its manipulation and management present significant logistical challenges; (also) the branch of computing [...]