L’algorithme de descente de gradient
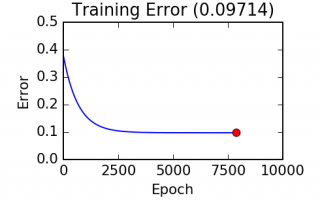
L'algorithme de descente de gradient est un algorithme itératif ayant comme but de trouver les valeurs optimales des paramètres d'une fonction donnée. Il tente d'ajuster ces paramètres afin de minimiser la sortie d'une fonction de coût face à un certain jeux de données. Cet algorithme est souvent utilisé en apprentissage machine dans le cadre de régressions non linéaires puisqu'il permet de rapidement trouver une solution approximative à des problèmes très complexes. Mon dernier article, Introduction à la régression linéaire, fait mention [...]