

Dans cet article, vous apprendrez ce qu’est que le multithread ou multicore, et dans quel cas utiliser l’un ou l’autre.
Votre ami nerd vous parle de sa déformation professionnelle tout le temps? À vouloir paralléliser et optimiser son temps? Vous souhaitez vous aussi comprendre et gagner du temps en parallélisant vos programmes en Python? Alors cet article est pour vous!
Vous allez pouvoir, grâce à une petite dose de parallélisme, de Python et de beaucoup d’amour, gagner énormément de temps. Le but étant ici de raccourcir les pauses café et de ne plus pouvoir regarder la Guerre des étoiles-épisode IV directement sur le terminal :
telnet towel.blinkenlights.nlMais vous apprendrez ici à regarder Star Wars et coder tout en buvant un café 😉
Il vous faut tout d’abord un peu de vocabulaire. Si vous savez ce qu’est la différence entre le multiCoeur et le multiThread, vous pouvez passer directement à la partie Python. Si vous savez programmer en Python vous pouvez passer directement à la partie « Module threading ». Si vous savez déjà programmer en Python ET que vous maitrisez parfaitement le module threading alors vous pouvez soit : ne pas lire cet article et gagner 38 minutes (temps estimé selon une étude bidon) soit : lire cet article et passer un bon moment.
-
MultiCoeur : Est-ce qu’on parle ici de pieuvres?
Le terme ‘coeur’ ou core en anglais est mal choisi. Nous préférons l’analogie avec le cerveau (vous me direz que la pieuvre a aussi plusieurs cerveaux). Votre ordinateur peut utiliser en même temps (on dit en parallèle) plusieurs programmes ou applications (mail, navigateur web, …). Imaginez que vous ayez plusieurs cerveaux, alors vous pourriez lire cet article et faire une transformation de bactéries en même temps.
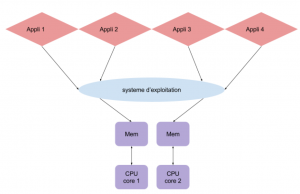
Le système d’exploitation qui peut être vu comme l’ordonnanceur, exécute les applications en les répartissant entre les differents coeurs (CPU). L’ordinateur peut alors diviser le travail entre chaque coeur et faire plusieurs choses en même temps. Dans cette image, ce système possède 2 coeurs, donc cet ordinateur peut utiliser les applications 1 et 2 en même temps, par exemple être sur internet et sur le terminal simultanément. -
MultiThread : Est-ce que l’on va parler ici de couture ?
Grâce au multithread, votre programme va pouvoir faire plusieurs tâches en même temps . Dans une application monothread, une tâche empêche les autres tâches de s’exécuter tant que cette première n’est pas terminée!!!
À l’inverse, une application multithread optimise l’efficacité de l’unité centrale parce qu’elle ne reste pas inactive et va s’exécuter en parallèle.
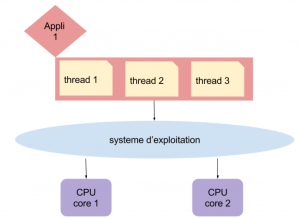
Ici, l’application contient 3 tâches qui vont être lancées en parallèle et,donc, avancer en même temps. Pour une même utilisation du CPU, on va pouvoir lancer 3 tâches à la fois. -
Rappel Python : Ah, les invertebrés, ça me connait
« Le terme Python est un nom vernaculaire ambigu désignant en français plusieurs espèces de serpents appartenant à différents genres des familles des Pythonidae et des Loxocemidae. Pythonest le nom scientifique d’un genre de serpents de la famille des Pythonidae.« — Wikipedia
Python est aussi un langage de programmation qui permet de faire des programmes cool pouvant être parallélisés. On parle ici de programmes et non pas de scripts. Si vous souhaitez apprendre le Python, nous vous recommandons : ce super livre.

C’est bon, vous êtes fin prêts pour l’aventure!!
Commençons par regarder les différences entre le mutilprocess et multithread au sein du même module « concurrent.futures » qui permet de paralléliser tant en threads qu’en processus.
from concurrent import futuresLe code qui suit est tiré du site :
Il a été légèrement modifié et commenté pour une meilleure lecture. Les images qui suivent sont les images originales de l’auteur.
L’auteur spécifie 5 ‘workers’, donc 5 threads/processus qui roulent en même temps pour 15 « itérations »
WORKERS = 5
ITERATIONS = 15
Voici la fonction utilisée :
def test_multithreading(executor, function):
start_time = datetime.datetime.now()
with executor(max_workers=WORKERS) as ex:
result = list(ex.map(function, itertools.repeat(start_time, iterations)))
start, stop = np.array(result).T
return start, stop
Pour une meilleure compréhension, voici une deuxième version (moins jolie) de cette fonction qui fait la même chose, mais qui est écrite avec des boucles « for »:
def test_multithreading(executor, function):
start_time = [datetime.datetime.now() for _ in range(iterations)]
with executor(max_workers=WORKERS) as ex:
processes = []
for st_time in start_time:
processes.append(ex.submit(function, st_time))
result = []
for p in processes:
result.append(p.result())
start, stop = np.array(result).T
return start, stop
Exemple d’appel à la fonction:
test_multithreading(futures.ThreadPoolExecutor, busy)« busy » étant une fonction qu’on définit ci-dessous.
« Idle » : Le programme effectue une pause de 2 secondess
« Busy » : Le programme effectue un (relativement) long calcul
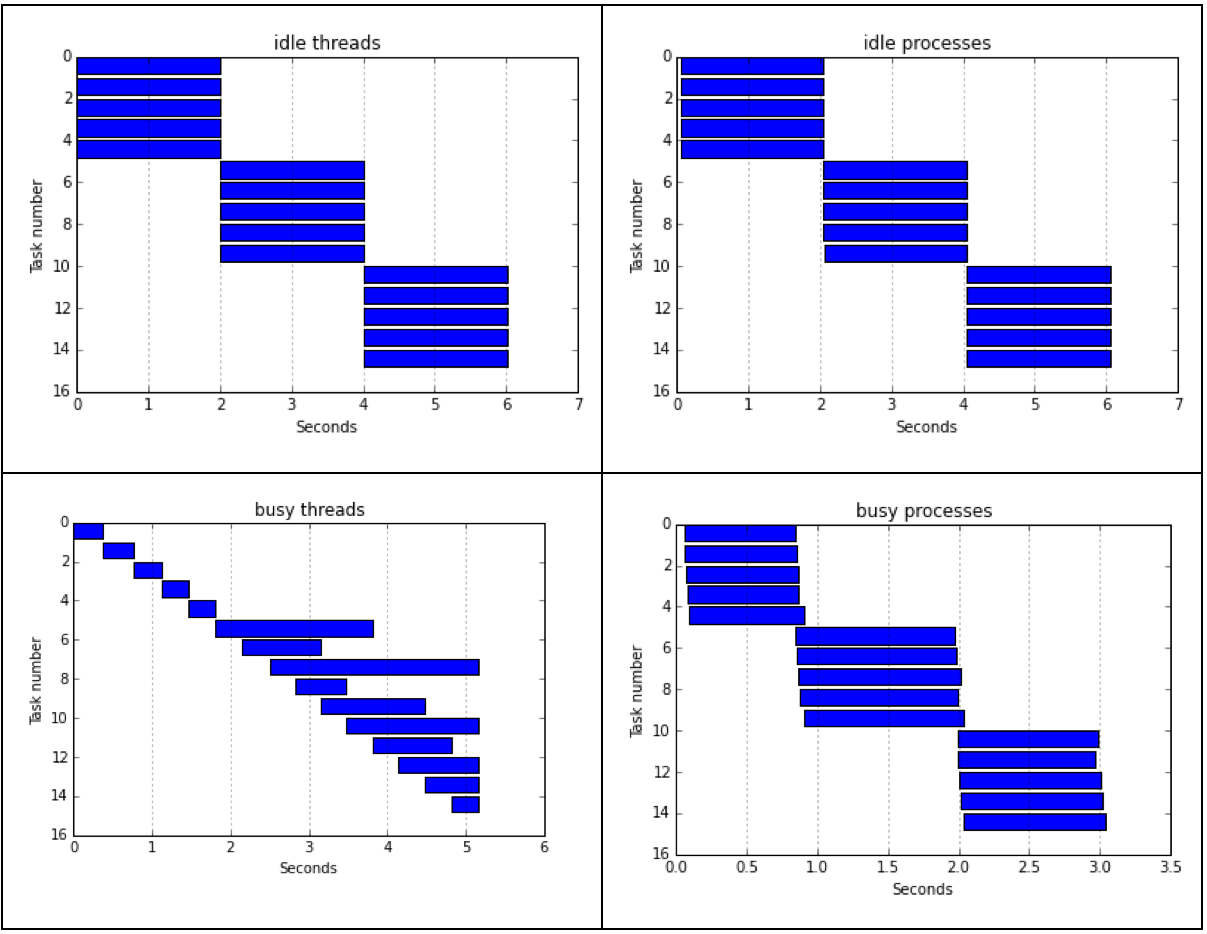
Résultats : Pour la version « idle », la vitesse d’execution des 5 threads vs processus est sensiblement la même, mis à part un léger retard lors du démarrage des processus.
Par contre, on remarque que lorsqu’il s’agit d’opérations coûteuses en mémoire, les threads sont bien moins performants que les processus.
Pour plus d’informations sur la provenance de ce code et de ces images, consulter le site.
Comme nous sommes sympas, nous vous avons concocté un petit tableau récapitulatif :
| Threads | Processus |
|---|---|
| Créer des threads est rapide | La création des processus est plus lente |
| Les threads utilisent une même mémoire:
→ La communication est rapide → Moins de mémoire est utilisée |
Les processus utilisent des espaces de mémoire séparés
→ La communication est lente et difficile → Une plus grande portion de la mémoire est utilisée |
| Roule sur un seul processeur | Prend avantage des différents CPUs et cores de la machine |
| Le Global Interpreter Lock (GIL) empêche l’exécution simultanée des threads | Les multiprocess sont indépendants l’un de l’autre, leur permettant ainsi de contourner le GIL |
| Très bonne méthode de communication! (exemple: un serveur qui demande des inputs à un script qui est en train de rouler) | Permet de faire gagner du temps en prenant avantage de toutes les capacités de la machine |
| Le module ‘threading’ est un outil très puissant qui contient un grand nombre de fonctionnalités | Le module ‘multiprocessing’ est conçu pour être aussi proche que possible du module ‘threading’ |
| Si un thread crash, tous les autres threads crasheront en conséquence | Un processus qui crash n’affectera pas les autres processus, puisqu’ils sont indépendants les uns des autres |
Tableau résumant les différences majeures entre multiprocess et multithread en Python.
Tout ça est bien beau, mais en pratique, il nous faut savoir comment utiliser les différents modules qui nous permettent de profiter de cette extraordinaire invention qu’est le parallélisme!
À notre connaissance, il existe essentiellement trois modules ‘pythoniens’ capables d’accomplir cette tâche :
- Le module multiprocessing
Nous vous conseillons d’aller voir un excellent article sur le sujet :
“Faites travailler vos CPUs !”
- Le module threading
Ce module est un excellent outil pour paralléliser des threads en Python. Il est fortement inspiré de Java, et fourni un réel arsenal d’outils pour les programmeurs expérimentés. Cependant, la richesse de ce module fait en sorte que ça reste quand même une librairie un peu complexe et relativement longue à maîtriser. Pour ceux qui ne souhaitent pas apprendre le module threading, il existe une sous-librairie, multiprocessing.dummy, permettant de créer des threads. Cette dernière peut être vue comme un clone de la librairie multiprocessing et permet d’utiliser la fonction « map » comme le ferait celle-ci (pour des exemples d’utilisation de « map », se référer à l’article cité dans la section précédente).
Voici un exemple d’appel à cette fonction :
from multiprocessing.dummy import Pool as ThreadPoolremarque : Nous avons inclu cette librairie « multiprocessing » dans cette section bien qu’elle ne fasse pas partie du module « threading » mais bien du module ‘multiprocessing’. Si nous avons fait ce choix c’est parce que « multiprocssing.dummy » permet de créer des threads.
- Le module concurrent.futures
Ce module est relativement récent, il est une simplification des 2 modules précédents. Mais ce n’est pas tout, pour chaque appel d’une fonction, un objet « futur » est créé, permettant de suivre l’évolution du processus (ou thread) et offre une plus grande liberté d’action. Il va de soi que cette méthode est plus lente que les précédentes.
Mais si vous devez investir du temps pour apprendre à maîtriser une librairie en Python, ce serait cette dernière.
Merci et félicitations d’avoir lu cet article jusqu’ici. N’hésitez pas à laisser un commentaire d’une quelconque nature: plus on aura de commentaires, plus nous pourrons fournir des articles de qualité!
Laisser un commentaire