

Let’s say all your results for a given project are stored in Excel files named exp1.xlsx, exp2_20170708.xlsx, exp_prolif_072017.xlsx… Inside file exp1.xlsx, you have this :
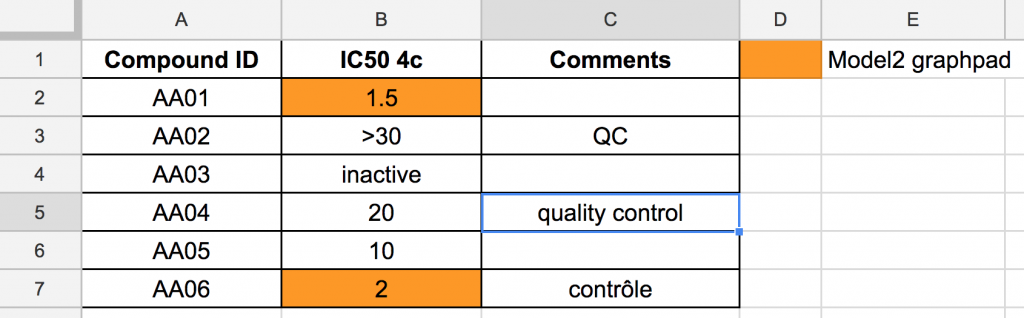
This might be a user-friendly result file but it is not “computer-friendly” file. Let’s suppose that you (or your boss) decide that you now need a database instead of the twenty-six different Excel files you have been using to store results. If all your files are similar to exp1.xlsx, you will have to put a considerable amount of time cleaning the data before even thinking of designing the schema of you database. This is also true if you want to subsequently analyse your data in R, for example.
In the example above, several elements are challenging for computer scripts:
- Numerical values are mixed with text
- Cells colour is a source of information in itself
- Different words are used to designate a single state (“control” in the example above)
As for the experiment itself, it would be hard to know the context in which the experiment was (type of samples, compound concentrations, type of assays, IC50 computation methods, etc.) since there is little information about it inside the file or even in the name of the file. Sure, you have an IC50, but without the related metadata, this value does not tell you much. You probably know all the conditions linked to it, but it’s not necessarily the case for all your collaborators.
So why not adopt good habits from the start? For example:
- Always keep a structured, computer readable file with the metadata. This file should be placed with the result files. It should describe the experiment (types of samples, assay, concentrations, etc.) and the content of the result files. Each column name should be explained if they are not sufficient by themselves: “IC50 4c”, what is 4c?;
- Use uniform and universally accepted vocabulary to allow easy text searching afterwards. In the above example, “Quality Control” should have been used everywhere;
- Do not aggregate information using colour or character formatting, such as bold or italic. A new column called “Method” containing the name of the method or a new column called “Used Model2 Graphpad” should be created to display which IC50 values were computed with Graphpad’s model2. These cells can be coloured as long as the information is also found as an actual value;
- Do not mix numerical and text values. Try computing the mean of the IC50 column from the above example in Excel… You will easily understand what I mean!;
- Think like a computer! Computers do not take decisions (at least, not yet!) and they do not guess what was intended. So be precise and accurate leaving no room for interpretation.
Here is what a more computer-friendly file might look like. It should be renamed IC50_cellLineX_20170710_GBoucher_1.xlsx and be associated with its metadata file.
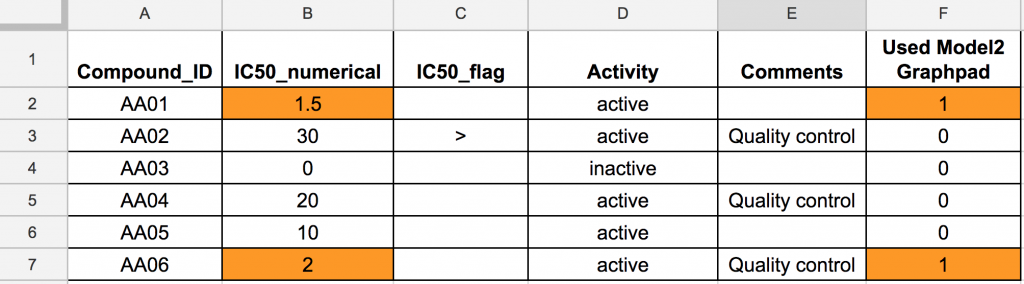
It is still very usable and pleasant for humans! So if you can, try to adopt good practices from the start.
Actually, good practices exist in all domains. In some domains, following them is mandatory. Think about the Standard Operating Procedures (SOPs) in clinical or pharmaceutical laboratories. In other domains, such as bioinformatics or computer sciences, they are encouraged but not always applied. Nevertheless, they can be of great value when collaborating with others or when revisiting an old project.
Excellent piece! Problems surrounding data recording are widespread yet largely preventable.