

Context:
AUC is an acronym for “Area Under the (ROC) Curve”. If you are not familiar with the ROC curve and AUC, I suggest reading this blog post before to continuing further.
For several projects, I needed to compute a large number of AUC. It started with 25,000, increased to 230,000 and now I need to compute 1,500,000 AUC. With so many AUC, the time to compute each one becomes critical. On the web, I don’t find much information about this specific subject, may be this is not a bottleneck generally met by the community.
So the goal of this blog post is to make a complete overview of the existing methods that can be use to compute AUC focusing on their executions time. Please, feel free to add a comment if I miss some of them.
Analysis:
Starting from a vector of scores (with labels):
| Label: | A | A | A | A | … | B | B | B | B |
| Score: | 10 | 20 | 15 | 5 | … | 8 | 12 | 9 | 3 |
I found three ways to compute an AUC:
- Area of a trapezoid: start by transforming the vector of values into a vector of coordinates (which represent the ROC curve) and use the formula to compute the area of a trapezoid.
- Concordance measure: compare each possible pairs (from labels) to count how many time Score(A) > Score(B)
- From a Mann Whitney u-test: use the U statistic.
Now, let’s find the fastest method using the estimation of the number of operations executed by each strategy. Basically, more operations imply more time. Before going further, note that estimating the number of operations is a huge subject called complexity, but in this case I propose to do it simply, like this:
- Concordance measure: Made n*m pairs comparisons, with n (resp. m) the number of sample A (resp. B). This method is classified in quadratic algorithms, the number of operations grows exponentially with the number of samples. To reduce the number of operations, we can compare a subset of pairs (n*m*p, with 0<p<1) and calculate an estimation. Each pair need to be taken randomly with replacement. But keep in mind that this trick trade accuracy for time, and finding the “optimal size” of the subset can be a complex question.
- U-test: To compute the U statistic, we mainly need to calculate a rank for each sample based on their scores, which can be done with a sorting algorithm in N*log(N) operations (with N=n+m).
- Area: Starting by a sort to transform the scores into coordinates, followed by the computation and the sum of N-1 trapezoid’s area. So we have N*log(N) + N operations.
{kind=link}
And the winner is … the u-test, who computes an AUC with the least operations and would be the fastest method. To be more concrete, I’ve implemented all these methods in python3 and obtain the figure below.
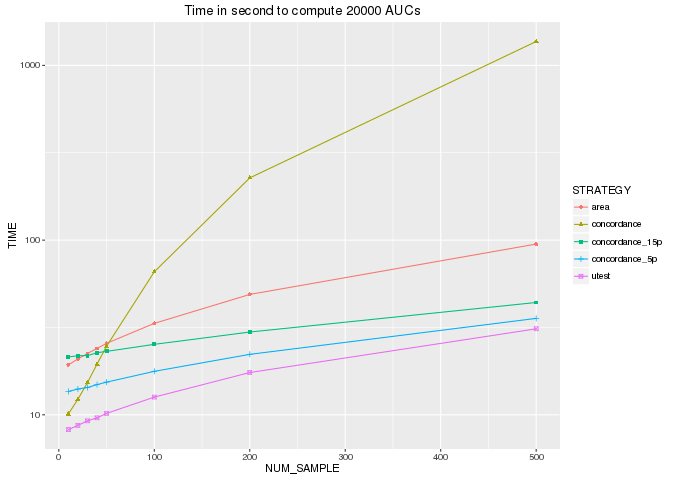
“concordance_15p” (resp. “concordance_5p”) represents the concordance method on a subset with p=0.15 (resp. 0.05).
As you can see:
- Mann Whitney u-test is the fastest method to compute an AUC, if you don’t need to display the ROC curve.
- The area method have the same shape than “utest” (both are linearithmic) and like we expect, it is around 2 times slower than the u-test method (N*log(N) + N = 2* N*(log(N)+1) )
- As we seen with the number of operations, the concordance method have an execution time who grows exponentially with the number of samples.
- The concordance method on subset is still slower than u-test. I don’t check the accuracy of the estimation, but I don’t see any advantage to use it and I don’t understand why this method is more represented in forums compared to u-test.
Below you can find the implementation of “utest” in R and python (all implementations are on my git).
| R | Python |
|
|
sources: stackexchange, wikipedia, stackoverflow
Thank you for this post! I had never heard of the Mann Whitney u-test and thus had no idea you could compute the AUC of a ROC curve without graphing the curve.
Awesome share. Thank you for this post!
It saved 1us of every AUC I wanted to calculate (1 billion ones in total :D)