Big data, big challenge – part 2
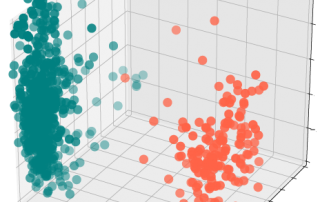
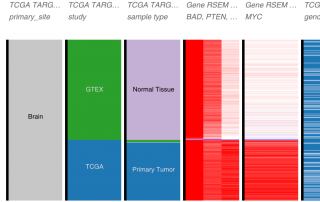
This post follows my previous post on big data. Even though the latter did not result in a big virtual discussion, I was pleased to read some comments regarding the situation in other areas of bioinformatics. Proteomics Mathieu Courcelles, bioinformatician at the proteomics platform, explained that mass-spectrometry driven proteomics has always generated 'big data', so this expression is not used in the field. As he said, Mass spectrometers are indeed instruments that generate a large volume of data 24/7. Early on [...]