

From August 21 to 25, IVADO and the MILA held their first edition of the École d’été francophone en apprentissage profond. The aim of this summer school was to “give [the participants] the theoretical and practical basis for understanding [deep learning]”.
A few members of the platform and myself participated to these five days of training.
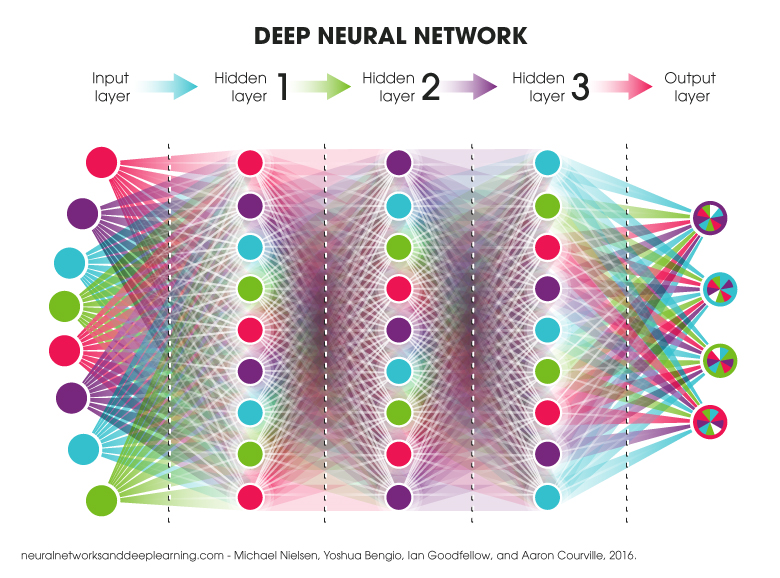
I must be honest, I was a little afraid of deep learning the first time it was presented to me. I found the concept fascinating, but I quickly faced a beautiful big wall when it came time to concretize the whole thing (in other words, when it came time to code). Then, slowly, I started to try out different things. I began with gradient descent, then I went on to more precise algorithms, and I even went as far as to play with a small convolutional network. All this to say that I overcame my initial reluctance, and was very happy to be able to participate in a week of training given by the IVADO/MILA.
The level of the classes taught was, in my opinion, a little bit above beginner: not too specialized nor a simple list of definitions. I have never taken courses on deep learning and I really enjoyed to be taught the basis in this manner. I am satisfied with what I have learned and recommend the experience to anyone who would like to be initiated to deep learning.
One of the main strengths of this week was, in my opinion, the “En pratique” sections. These short presentations of 15 to 20 minutes were pure application! I really enjoyed the hierarchical order in which the different subjects were presented: at the beginning of the week, we talked about the data (big data) and the libraries to use; then at the end of the week, we explored some tools exploiting deep learning approaches in the medical field (for example, labeling malign and benign polyps) and some resources available to startups.
Finally, here are some key concepts and general ideas that have particularly resonated with me. Maybe they will be useful to you too!
- A good question to ask to know whether deep learning is adequate for our problematic: is there some vagueness surrounding the solution we are looking fore? If so, deep learning could help; if not, there may already be formalized rules surrounding what we are looking for.
- It is important to always keep in mind that if the problem is complex, the network to solve it will probably be as complicated.
- Data should be viewed in terms of value rather quantity… Even though it is necessary to have a lot of data!
- Although there is no a good universal value for the learning rate, a valid first estimate would be the maximal second derivative of our equation.
- When validating a network, we should look carefully at the examples that give rise to large errors; it may also be good to “break” the network in order to fully understand what the algorithm is doing.
- When starting in deep learning, it is helpful to use pre-fabricated models available online, and/or start by imitating the experts (github is great source for sample codes); it is also interesting to test various tools/approaches and play around with various datasets from different sources.
I really enjoyed this week of learning! In the end, do not be afraid to try something new, as frightening as it may seem at first 😉
Leave A Comment