

Du 21 au 25 août se tenait la toute première édition de l’École d’été francophone en apprentissage profond donnée par IVADO et le MILA. Le but de cette semaine était de « [donner aux] participants les bases théoriques et pratiques nécessaires à comprendre le domaine [de l’apprentissage profond] « .
Quelques membres de la plateforme et moi-même avons participé à ces cinq jours de formation.
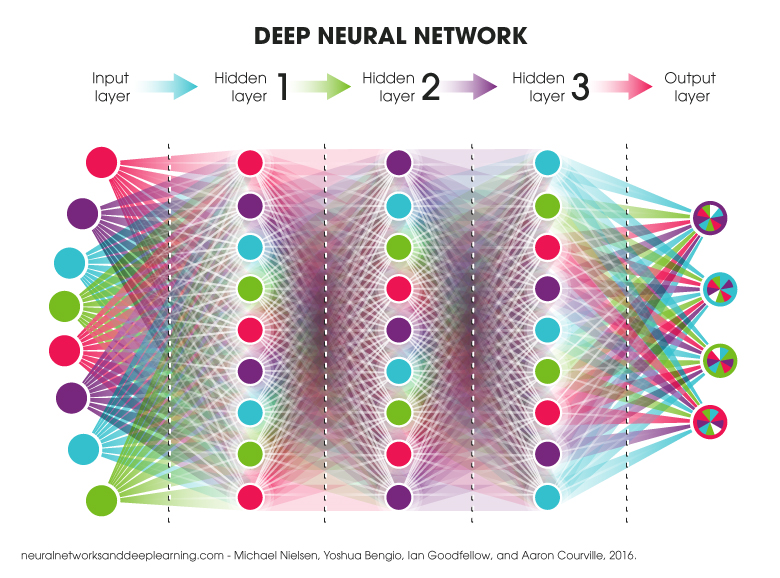
Je dois être bien honnête, l’apprentissage profond me faisait un peu peur les premières fois que j’ai été exposée au sujet. Je trouvais le concept fascinant, mais je me butais rapidement à un beau gros mur lorsque venait le temps de concrétiser le tout (en d’autre terme, coder). Puis, tranquillement, je me suis mouillée les pieds. J’ai commencé avec des descentes de gradient pour ensuite aller vers des algorithmes un peu plus pointilleux. Je suis même allée jusqu’à jouer avec un petit réseau à convolution. Tout ça pour dire que j’ai surmonté ma réticence première et que j’étais bien heureuse de pouvoir participer à une semaine de formation donnée par le MILA/IVADO.
Le niveau des blocs d’enseignement était, selon moi, une petite coche au dessus du niveau Débutant: pas trop poussé, mais juste assez pour faire aller nos neurones (le jeu de mot est fait!). Je n’ai jamais suivi de cours sur le sujet de l’apprentissage profond. J’ai beaucoup apprécié me faire enseigner les bases de cette façon. C’est d’ailleurs la raison principale de mon inscription à l’école d’été. Je suis satisfaite de ce que j’ai pu en tirer et recommande l’expérience à tout ceux qui aimeraient aborder le sujet.
Selon moi, un des points forts de la semaine était les blocs « En pratique ». Ces courts blocs de 15-20 minutes étaient pure application! Ce que j’ai particulièrement apprécié était la hiérarchie des sujets présentés: en début de semaine nous parlions des données (mégadonnées) et des biobliothèques à utiliser; puis à la fin de la semaine, nous explorions des outils utilisant l’apprentissage profond dans le domaine médical (par exemple, la reconnaissance de polypes malins et bénins) et les ressources mises à la disposition des startups.
Pour terminer, voici quelques concepts clés et grandes lignes que j’ai retenus. Peut-être qu’ils vous seront utiles à vous aussi!
- Un indice pour déterminer si l’apprentissage profond est adéquat pour notre problématique : y a-t-il du flou entourant la réponse que l’on recherche ? Si oui, l’apprentissage profond pourrait nous aider; si non, il existe peut être déjà des règles formalisées.
- Toujours garder en tête que si le problème est compliqué, le réseau risque de l’être tout autant.
- Essayer de voir les données en terme de valeur plutôt que de quantité… Bien qu’il faut avoir quand même beaucoup de données!
- Garder en tête qu’il n’est pas toujours évident d’obtenir les paramètres optimaux générant la plus petite erreur: il peut être acceptable de chercher à avoir une minimisation approximative.
- Bien qu’il n’existe pas une bonne valeur universelle pour le pas de gradient (learning rate), une estimation première est la dérivée seconde maximale de notre équation.
- Lorsque l’on valide un réseau, bien regarder les exemples qui donnent des erreurs plus grandes; il peut être aussi bien de « casser » le réseau pour bien comprendre ce qui se passe.
- Lorsque l’on commence en apprentissage profond, utiliser des modèles pré-fabriqués en ligne et/ou commencer en imitant le code d’experts (fouiller sur GitHub); il est aussi intéressant de s’amuser et de tester différents outils/approches sur des jeux de données de divers provenances.
Tel que mentionné plus haut, je recommande cette expérience! N’ayez surtout pas peur d’essayer quelque chose de nouveau, aussi effrayant que cela puisse sembler aux premiers abords 😉
Laisser un commentaire