

Il est souvent plus facile d’interpréter des données biologiques lorsqu’il est possible de les visualiser à l’aide d’une représentation graphique. Cela peut être fait via l’exploitation de différentes options de ggplot2, un progiciel pour la représentation graphique en R. Dans le billet qui suit, je vous présenterai quelques-unes de mes astuces favorites pour la visualisation de données: rien de trop poussé ou complexe, parfait pour les utilisateurs avancés de R, tout comme les utilisateurs un peu plus débutants! Les extraits de code sont tous en R. De plus, la library ggplot2 doit être installée et chargée.
install.packages("ggplot2")
library(ggplot2) Pour illustrer l’usage des différentes astuces, nous avons généré un jeu de données aléatoir et normalement distribué. Chaque point de donnée (x,y) est associé à un Groupe classificateur aléatoire (Group1, Group2, Group3 ou Group4) ainsi qu’à un Sous-groupe classificateur aléatoire (GroupA ou GroupB). Les valeurs et groupements sont conservés dans un data frame.
df.data <-data.frame("x" = data.x, "y" = data.y, "group" = data.group, "subgroup" = data.subgroup) Accentuer une partie des données
Accentuer certaines données peut aider à identifier ainsi qu’à localiser certains points parmi le jeu de données complet. Cela peut aussi permettre de détecter des regroupements de points parmi les données. Il existe deux approches principales pour accentuer une portion des données. La première approche se base sur la classification de chaque point. Souvenez-vous que chacun de nos points aléatoires s’est vu attribuer un Groupe. Nous voulons maintenant attribuer une couleur à ces points qui est spécifique à chacun des Groupes. Lorsque nous définissons les composantes esthétiques de notre graphique, i.e. les valeurs de x et y, nous spécifierons que la couleur d’un point est définie par le Groupe de ce dernier. La même chose pourrait être faite selon les Sous-groupes. Cette approche fonctionne bien lorsqu’appliquée à un nuage de points.
ggplot(data = df.data) +
geom_point(aes(x = x, y = y, colour = group)) 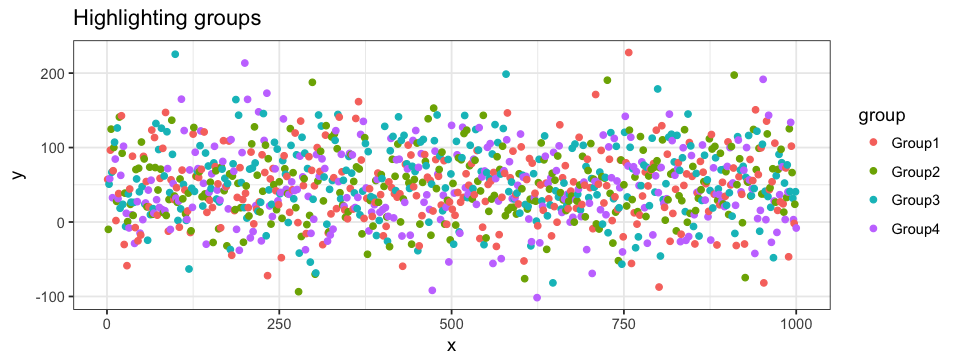
La deuxième approche peut accentuer des points autant selon leur classification que selon leurs valeurs. Pour ce faire, nous utilisons la fonction subset de R. Nous pouvons, par exemple, accentuer tous les points du Group1. En faisant cela, tous les autres Groupes sont regroupés en une seule entité.
ggplot(data = df.data) +
geom_point(aes(x = x, y = y)) +
geom_point(data = subset(df.data, group == "Group1"),
aes(x = x, y = y),
colour = "pink")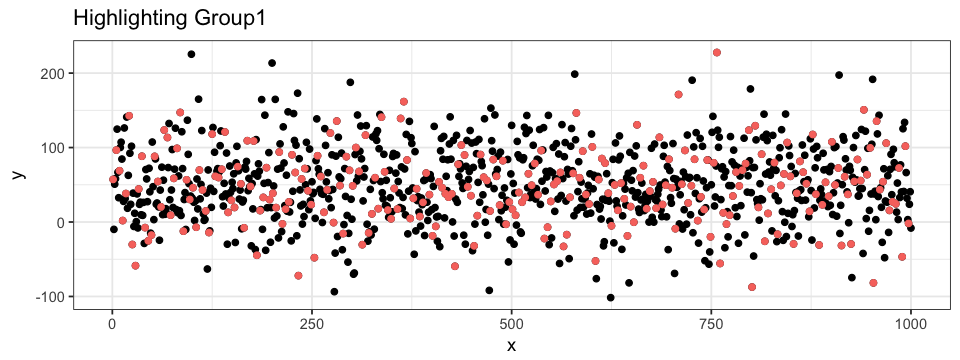
Il est aussi possible de définir un sous-ensemble (subset) à partir d’un autre sous-ensemble, ce qui permet d’accentuer certains points de donnée de façon plus spécifique. Par exemple, nous pouvons mettre en évidence les points contenue dans une région précise du graphique. Nous pouvons aussi superposer différentes couches de points : une avec toutes les données (en noir) et une avec seulement un sous-ensemble (en rose). Notons que l’ordre des couches est important dans ce dernier cas (essayez d’interchanger les deux couches geom_point du code ci-dessous…).
ggplot(data = df.data) +
geom_point(aes(x = x, y = y)) +
geom_point(data = subset(subset(data = df.data, y > 0 & y < 100), x > 250 & x < 375),
aes(x = x, y = y),
colour = "pink")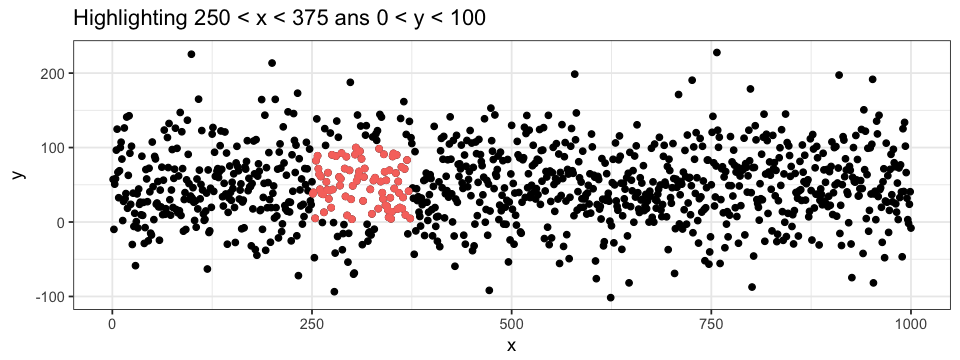
Pour tirer encore plus d’information de notre graphique, nous pouvons combiner les deux approches d’accentuation i.e. pour les points d’une région précise du graphique, leur attribuer une couleur spécifique à leur classification.
ggplot(data = df.data) +
geom_point(aes(x = x, y = y)) +
geom_point(data = subset(subset(data = df.data, y > 0 & y < 100), x > 250 & x < 375),
aes(x = x, y = y, colour = group))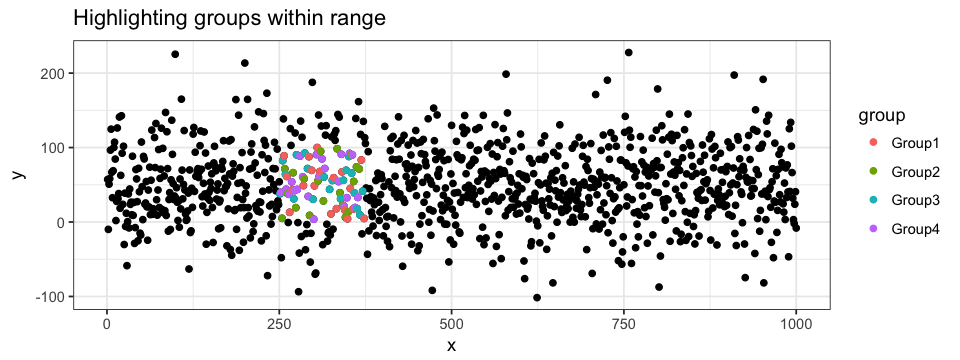
Annoter le graphique
L’annotation d’un graphique peut être très utile! J’utilise principalement trois formes d’annotation: l’étiquetage, l’ajout d’une ombre, et les segments. J’étiquette souvent des points de données pour une certain gamme de valeur (les valeurs extrêmes, par exemple). Il est possible d’étiqueter tous les points, mais je trouve souvent le graphique difficile à interpréter dans ce genre de situation: je ne vois qu’un seul gros nuage de mots empilés les uns par dessus les autres! Bien entendu, si les données sont clairsemées, l’étiquetage de tous les points peut être très informative. Un moyen simple d’étiqueter les données est d’ajouter une couche geom_texte. Cependant, je vous suggère de plutôt utiliser ggrepel (notons que cette librairie doit premièrement être installée et chargée). Cette librairie est conçue pour gérer la superposition d’étiquettes générées par geom_texte. Pour faciliter la visualisation, nous pouvons mettre en évidence (tel que décrit dans la section précédente) les points étiquetés.
install.packages("ggrepel")
library(ggrepel)
ggplot(data = df.data) +
geom_point(aes(x = x, y = y)) +
geom_point(data = subset(subset(data = df.data, x < 500 & x > 250 & < -50),
aes(x = x, y = y),
colour = "pink") +
geom_texte_repel(data = subset(subset(data = df.data, x < 500 & x > 250 & < -50),
aes(x = x, y = y, label = group),
colour = "pink")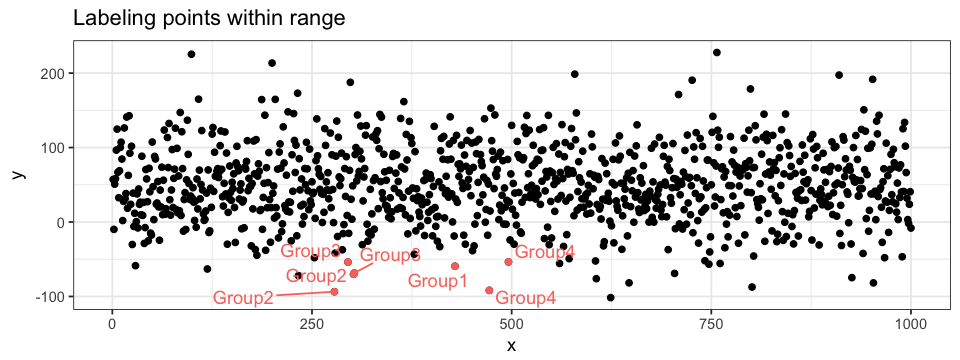
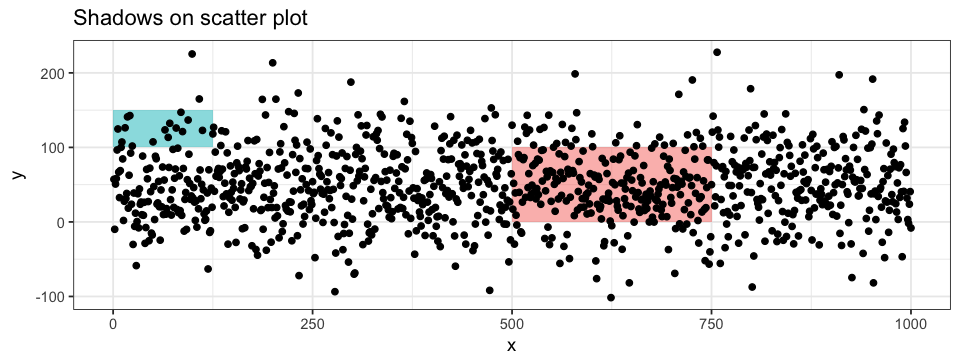
Une autre approche pour l’annotation d’un graphique est par l’ajout d’une ombre sur une une section précise de la figure. Pour ce faire, nous pouvons utiliser la fonction annotate de ggplot2. L’ombre sera appliquée à une portion du graphique délimitée par des valeurs xmin, xmax, ymin et ymax. Les ombres peuvent être appliquées autant sur des nuages de points que sur des histogrammes (BONUS: J’ai ajouté une annotation texte sur l’histogramme…). L’ordre des couches est encore une fois très important !
ggplot(data = df.data) +
annotate("rect", xmin = 500, xmax = 750, ymin = 0, ymax = 100,
alpha = 0.5, fill = "pink") +
annotate("rect", xmin = 0, xmax = 125, ymin = 100, ymax = 150,
alpha = 0.5, fill = "turquoise") +
geom_point(aes(x = x, y = y))
ggplot(data = df.data) +
annotate("rect", xmin = 46.05, xmax = 81.04, ymin = 0, ymax = 55,
alpha = 0.5, fill = "pink") +
annotate("rect", xmin = 81.04, xmax = 235.67, ymin = 0, ymax = 55,
alpha = 0.5, fill = "turquoise") +
annotate("text", x = 46.06, y = 58,
label = "Q2") +
annotate("text", x = 81.04, y = 58,
label = "Q3") +
geom_histogram(aes(x = y))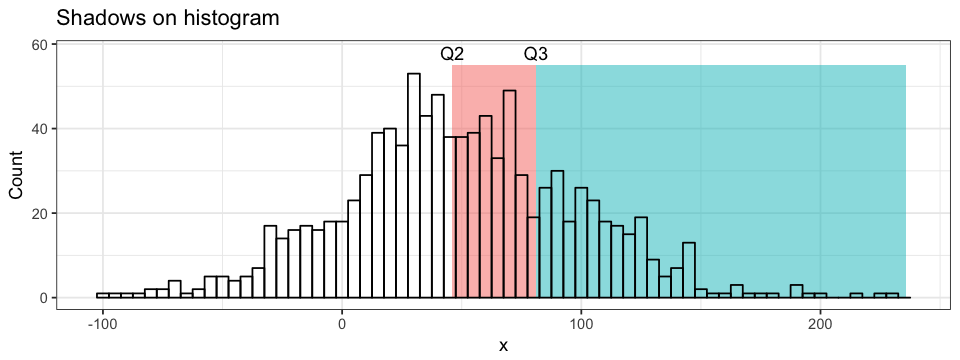
Enfin, certaines informations telles que les moyenne, écart-type ou limites d’intervalle de confiance peuvent être représentées adéquatement par des segments. Il y a trois fonctions principales pour dessiner de tels segments: geom_hline, geom_vline et geom_segment. Les deux premières sont pour les segments sans limite, interceptant l’un des deux axes(v pour vertical et h pour horizontal), tandis que la troisième est pour tout type de segment allant de (x, y) à (x', y'). Les segments interceptant un axe sont utiles dans la représentation des moyennes et des limites d’intervalle de confiance, par exemple. D’un autre côté, si nous voulons lier un point de donnée à ses coordonnées à même les axes, nous pouvons combiner deux segments avec limites. Notez l’utilisation de Inf dans le code ci-dessous et son effet sur le graphique généré. Je préfère définir mon x ou y avec -Inf plutôt qu’avec les valeurs minimales de chacun des axes: (1) nous n’avons pas à trouver manuellement ces valeurs minimales et (2) les segments interceptent un des axes tout en ayant une limite à l’autre extrémité (par défaut ggplot2 ajoute un certain espace entre les valeurs extrêmes des axes et les axes mêmes).
ggplot(data = df.data) +
geom_hline(yintercept = mean(df.data$y), # for vertical intercept: geom_vline(xintercept = x)
colour = "pink") +
geom_segment(aes(x = 752, xend = 752, y = -Inf, yend = 145),
colour = "turquoise",
linetype = "dashed") +
geom_segment(aes(x = -Inf, xend = 752, y = 145, yend = 145),
colour = "turquoise",
linetype = "dashed") +
geom_point(aes(x = x, y = y))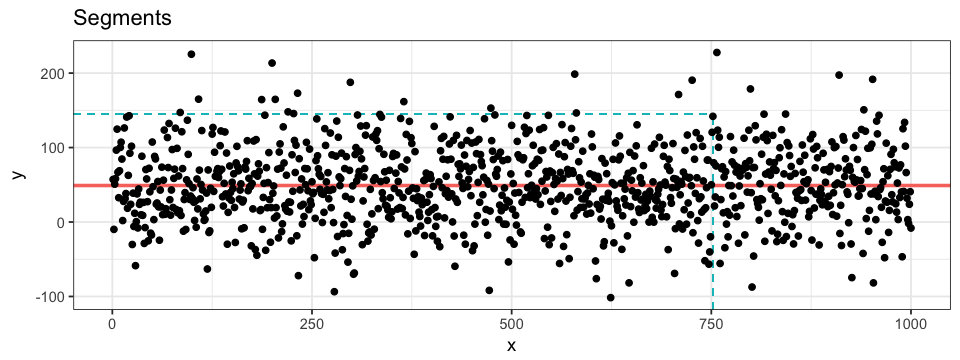
Facettes spécifiques à la classification des données
Dans la première section, nous avons illustré comment associer une couleur à chacun de nos Groupes. Le graphique résultant peut être très chargé et nous finissons par ne gagner aucune nouvelle information. Une façon de contourner ce problème est de générer un graphique pour chaque indentifiant classificateur. Pour ce faire, il n’est pas nécessaire de générer de nouveaux data frames ou des graphiques indépendants. Il est possible de diviser une seule figure en plusieurs différents facettes contenant chacun un sous-graph spécifique à un groupe de classification. La couche geom se définie normalement: la magie est dans la couche facet ! facet_wrap nous permet de définir un identifiant classificateur ainsi que le nombre de colonnes de notre figure principale. Puisque nous avons 4 Groupes et donc 4 sous-graphs, nous utiliserons 2 colonnes et la figure résultante sera organisée en 2×2 sous-graphs. Les sous-graphs d’une même rangée partageront l’axe des y, tandis que ceux dans une même colonne partageront l’axe des x.
ggplot(data = df.data) +
geom_point(aes(x = x, y = y)) +
facet_wrap(~ group, ncol = 2)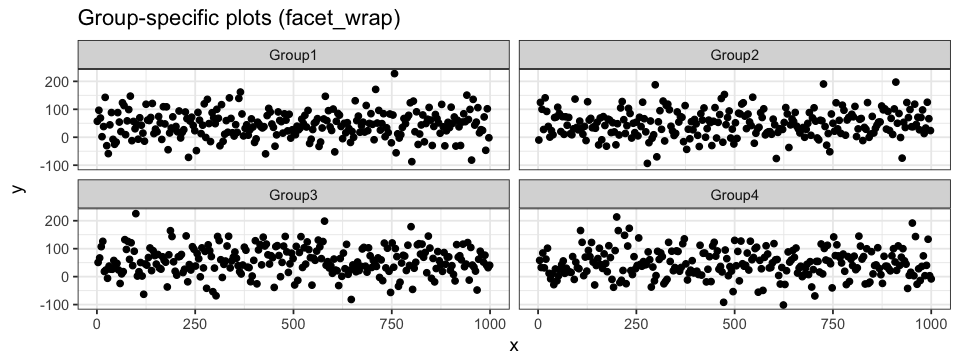
facet_grid peut également être utilisé. La différence principale avec grid_wrap est que les sous-graphs seront répartis soit sur une même rangée (. ~ group), soit dans une seule colonne (group ~ .). ~ peut être interprété comme contre et . comme tout. Chaque sous-graph partage les mêmes axes. Cela peut être changé en définissant le paramètre scale avec "free_x" (voir le code ci-dessous) ou avec "free_y". Lorsque nous définissons des attributs de couleur aux données, ceux-ci seront appliqués à tous les sous-graphs.
ggplot(data = df.data) +
geom_point(aes(x = x, y = y, colour = subgroup)) +
facet_grid(. ~ group, scale = "free_x")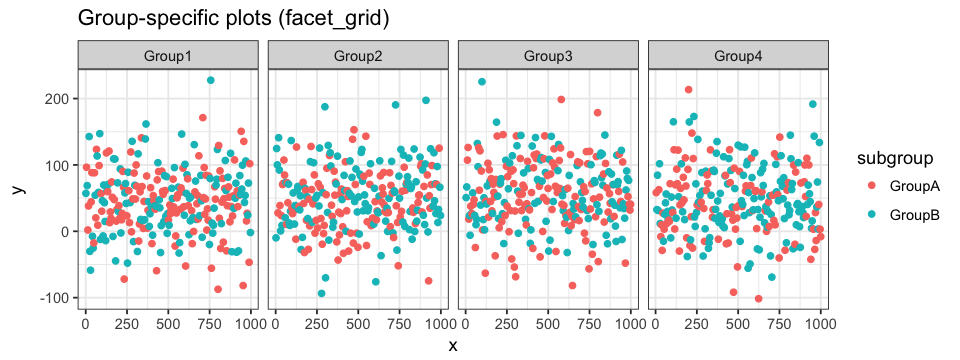
Dans le cas où nos données ont plusieurs identificateurs de classification, tel que dans notre exemple, nous pouvons aussi générer des facettes représentant des sous-classifications à l’intérieur même d’une classification plus large. Par exemple, nous voudrions analyser la distribution des valeurs pour chaque Sous-groupe à l’intérieur de chaque Groupe. Pour se faire, nous évaluerons subgroup ~ group ce qui résultera en une figure contenant 8 sous-graphs étalés sur 2 rangées (nombre de Sous-groupes) et 4 colonnes (nombre de Groupes).
ggplot(data = df.data) +
geom_histogram(aes(x = x, y = y, fill = group),
colour = "black",
binwidth = 15) +
facet_grid(subgroup ~ group, scale = "free_x")
Attributs spécifiques à une facette
Nous avons mentionné que les attributs de couleurs (comme tout autre type d’attributs) sont appliqués uniformément à toutes les facettes de la figure. Dans certains cas, cela est utile; dans d’autres, nous pourrions vouloir représenter des attributs spécifiques à chacune des facettes, de façon indépendante. Regardons un exemple simple dans lequel nous dessineront un segment représentant la moyenne de chaque facette, ainsi qu’une section ombragée commune à toutes ces facettes.
Nous devons premièrement calculer la moyenne de chaque paire (group, subgroup). Pour se faire, nous utilisons la fonction aggregate de R. Celle-ci regroupe des valeurs selon certains identificateurs de classification, puis applique une fonction donnée aux sous-ensemble de données résultant.
mean.data <- aggregate(x = df.data$y, # use the y values
by = df.data[c("group", "subgroup")], # group by Group and then by Subgroup
FUN = function(x) {
signif(mean(x), 4) # calculate the mean keep 4 significant numbers
}
)Pour faciliter la manipulation de notre data frame mean.data et éviter toute confusion, renommer les colonnes.
colnames(mean.data) <- c("group", "subgroup", "average")Nous pouvons maintenant générer la figure !
ggplot(data = df.data) +
# y-intercept for facet-specific average
geom_hline(data = mean.data,
aes(yintercept = average), # column of mean.data
colour = "pink") +
# writing the facet-specific average
annotate("text", x = 900, y = -120, # bottom right corner of facet
label = mean.data$average,
colour = "pink") +
# shadow common to all facets
annotate("rect", xmin = 225, xmax = 275, ymin = -Inf, ymax = Inf,
alpha = 0.5,
fill = "turquoise") +
# data points
geom_point(aes(x = x, y = y)) +
# facets
facet_grid(subgroup ~ group, scale = "free_x)L’ombre turquoise est la même pour les 8 sous-graphs. Le segment rose interceptant l’abscisse ainsi que les valeurs des moyennes sont spécifiques à chaque facette.
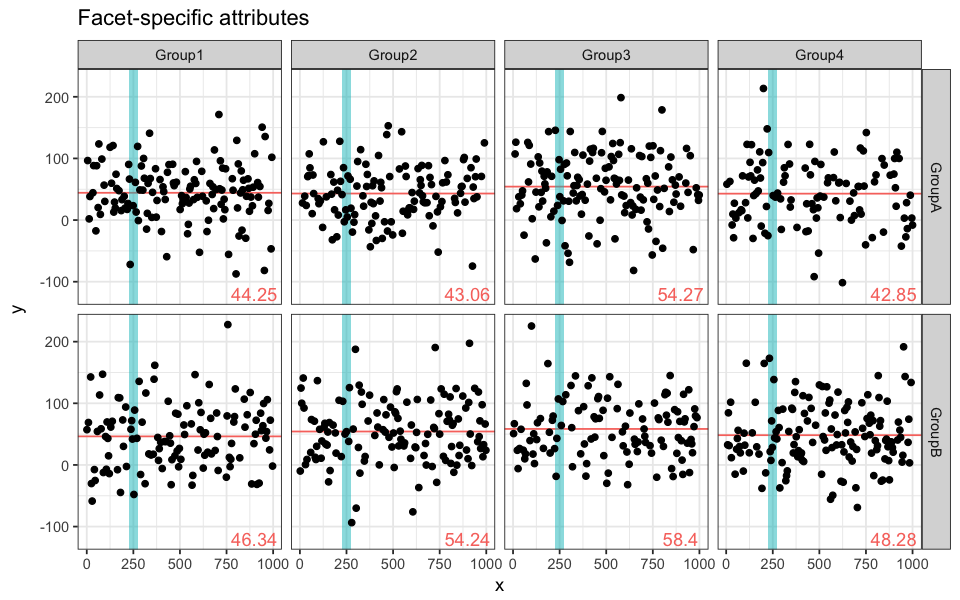
Les astuces présentées dans ce billet ne représentent qu’une petite fraction de que R peut offrir en matière de visualisation de données! Elles sont cependant très utiles et pour la plupart relativement simples à implémenter: elles peuvent utilisés comme point de départ lors de l’analyse de nouvelles données!
Très bon article Caroline!