

La première chose que j’ai appris à faire dans R est de charger un tableau de données. D’habitude, l’aventure R commence avec l’aide d’une personne plus expérimentée qui vous montre comment charger vos données dans le logiciel. Typiquement, la commande requise s’apparente à :
data<-read.table("~/dossier/datafile.txt")
Vous allez sûrement ajouter plusieurs autres paramètres aux parenthèses, tels que « row.names=0 » ou « header=TRUE » ou, « sep="\t"« , pour s’assurer que le fichier est lu correctement.
Cette manière de fonctionner est parfaitement correcte pour de petits jeux de données.
Cependant, pour maximiser votre temps, explorons les problèmes les plus communs et surtout leurs solutions.
Problème #1: Toutes les données sont dans une colonne!
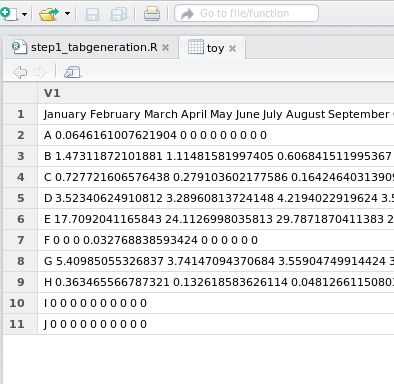
Solution: Ceci est très commun. Vous devez spécifier le séparateur!
Ceci est fait utilisant le paramètre sep="XXX" dans la fonction read.table(). À la place des XXX, vous devez mettre le séparateur de vos données. Typiquement, c’est soit un point-virgule (;) ou une virgule (,)
Problème #2: R n’a pas compris que j’ai des noms de colonnes et de rangées et il les a mis dans le tableau.
Solution: Ceci est rare mais facilement corrigé. Vous devez spécifier que vous avez des noms de colonnes (header=TRUE) et de rangées (rownames=1) dans votre fonction read.table()
Problème #3: Mon tableau est chargé mais les données sont sous la forme « factor » et je ne comprends pas pourquoi!
> data<-read.table("data.txt")
> class(data[,1])
[1] "factor"Solution: Dites à R que vous ne voulez pas de facteurs! Le paramètre as.is peut vous aider.
Note à propos des facteurs: Bien qu’elle soit parfois très utile, cette classe de données peut s’avérer difficile à gérer, surtout lorsqu’on veut faire des calculs sur des valeurs numériques dans le tableau. La fonction read.table() de R convertit par défaut toutes les valeurs en facteurs.
> data<-read.table("data.txt",as.is = TRUE)
> class(data[,1])
[1] "character" Problème #4: Mon tableau prend trop de temps à charger!
Solution: R est efficace dans le chargement de données lorsqu’on limite sa nécessité à prendre des décisions. En d’autres mots, tel que vu dans le problème #3, R convertit les données en facteurs. Ceci rajoute considérablement de temps de calcul.
Toujours pas convaincu? Voici une évaluation de performance:
data.txt contient un jeu de données RNASeq de 21024 genes pour 3080 patients.
> data<-read.table("data.txt",header=TRUE,sep="\t")
> elapsed
771.274 seconds
> data<-read.table("data.txt",header=TRUE,as.is=TRUE,sep="\t")
> elapsed
184.764 seconds
On observe une différence de temps de chargement de 4 fois! Vous pourriez couper dans votre temps de chargement encore davantage si vous sauvegardez votre tableau en format RData (rda).
> load("data.rda")
> elapsed
35.915 seconds
Mais bien sûr, ceci implique de l’avoir chargé au moins une fois dans R…
Je vous encourage à explorer les autres options de la fonction read.table(), vous serez surpris!
Une note concernant la fonction read.delim() : cette fonction est un « wrapper » de la fonction read.table() contenant les paramètres à usage courant. Utilisez-la à vos risques 🙂
Cool article 🙂
Une autre alternative à as.is=T pour réaliser des gains en performance serait de spécifier le type des données contenues dans les colonnes à l’aide du paramètre « colClasses »..
Mais il faut alors connaitre la nature de ces données au préalable !
Je ne comprends pas la note à propos de read.delim? Je l’utilise pour lire des fichiers .txt. Qu’est-ce que tu veux dire par « Utilisez-la à vos risques »? 🙂