Le surapprentissage et la régularisation
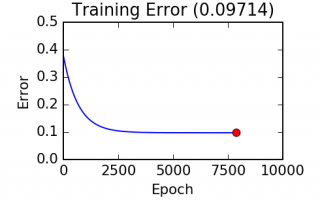
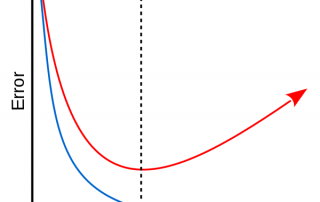
Cette série d'articles sur l'apprentissage machine ne serait complète sans y couvrir le surapprentissage et la régularisation. Le surapprentissage L'une des difficultés rencontrée lors de l'application de techniques d'apprentissage machine est le surapprentissage. Plus les techniques utilisées sont puissantes (grand nombre de paramètres libres), plus nous sommes susceptibles au surapprentissage. Lors du surapprentissage, le modèle diverge du principe du rasoir d'Occam en augmentant si bien son niveau de complexité qu'il finit par essentiellement mémoriser chaque détails de l'ensemble d'entraînement. Un modèle [...]